從生成語言學到自然語言處理(一):LLM和人類一樣嗎?
句法語意
科技應用
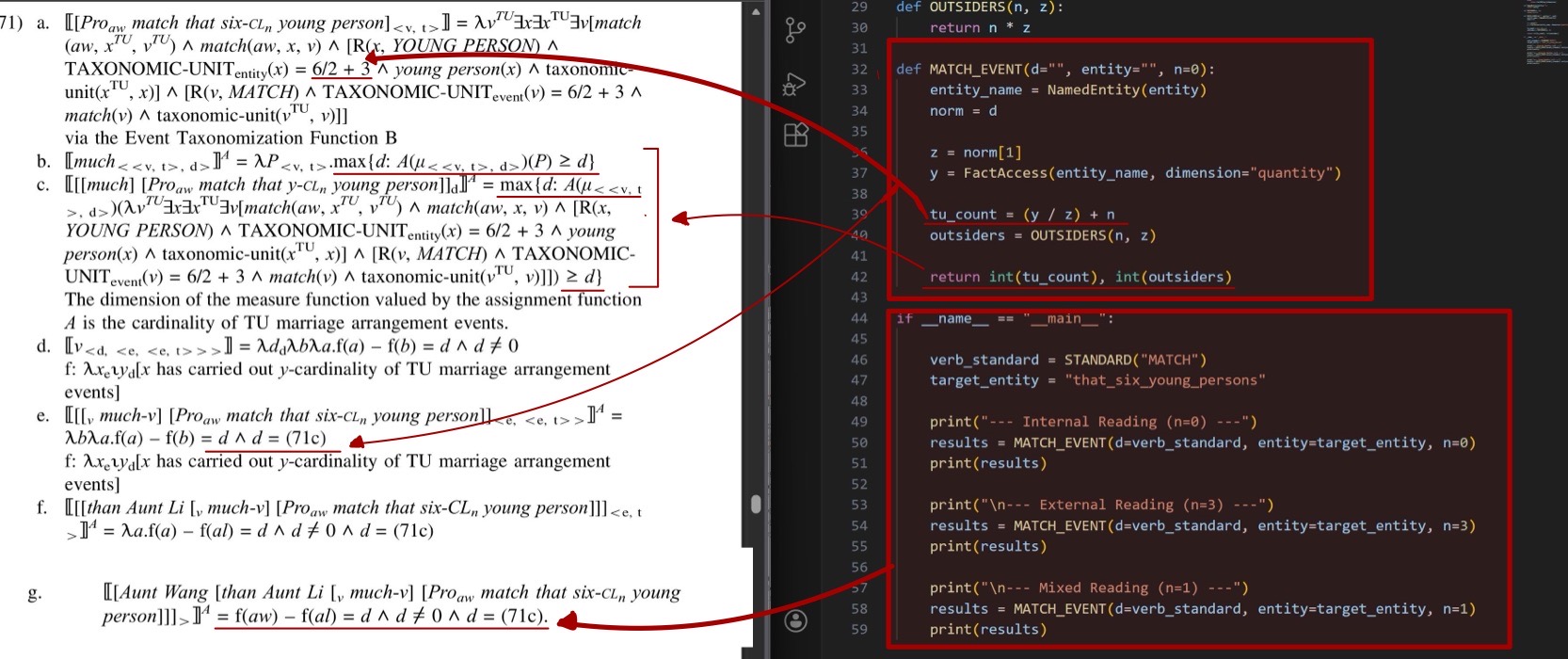
現在的生成式人工智慧能做到的事情越來越多,也越做越好。像是ChatGPT這樣的大型語言模型應用,從一般的問答、文章翻譯、摘要到檢查,甚至程式碼的撰寫,都能幫上忙。而身為語言學研究所的學生,我對於機器和資訊系統學習人類語言這件事情感到驚奇之餘,也很好奇 LLM 和人類在「語言知識的儲存表徵與運用機制」的差異究竟在哪裡?