

從生成語言學到自然語言處理(三):語法檢查任務的實作
我們進行這個實驗並不是想表達 LLM 不好,而是想實際應用簡單的語言學知識,驗證這些形式化的分析是否真的能實現「在接受這麼少的前提的情況下,知道這麽多」的效果。我們的實驗成果顯示 pyLiteracy 在文法檢查這類小型 NLP 任務中的表現十分出色。最重要的是,仰賴更貼近人類對語言的理解方式,它能用相比於 LLM 而言,非常非常少的資源就完成任務,在這個專案中,我們用非常非常少的語言學知識就省下了非常多的資源。

我們可以進一步試想,如果生成語言學家 [1] 針對「人類語言」的分析是對的,並且他們用的方法也符合科學方法,則我們是否就能讓機器像人類一樣,仰賴極少量的資源來掌握語言呢?以「語法檢查」這樣簡單的 NLP 任務為例,許多專案示範中,工程師通常會在前處理階段移除停用詞(stop words),這些詞往往是根據齊夫定律(Zipf's Law)在文本中高頻出現的詞彙 [2]。在字串預測的框架下,高頻停用詞可能會增加模型預測的雜訊。然而,仔細檢視後會發現,這些高頻詞大多為「的」、「在」、「很」、「這」、「那」等功能詞。如果能妥善利用這些功能詞,NLP 程式是否能像人類一樣,以功能詞為支點,更高效地拆解與理解文本呢?
我和一些夥伴對此想法做了一個實驗型的開源專案,PyLiteracy 以上到下(top-down)的方式處理語法檢查任務,以現代語言學研究文獻為基礎,在掌握特定目標詞彙語意功能、語法限制,以及使用規範等相關知識的前提之下,直接將相關知識建入模型中,作為模型給出答覆的唯一判斷依據。這種作法能確保模型輸出說明之正確性及穩定性之外,亦貼合人類母語者依照語感所統整出,針對繁體中文語法的特性及規範。
以常用字「在」為例,根據鄧守信 2018年的《當代中文語法點全集》,「在」的主要常見語意功能有以下五種,列舉於下例 :
「在」的常見語意功能:
a. 引介某人或某事的地點 (‘zai’ introduces the location of someone or something)
b. 引介某活動的地點 (‘zai’ marks the location where and activity takes place)
c. 指某活動在現在或指定時間點上正在進行 (‘zai’ before a VP indicates an ongoing activity taking place at the present (default) or at a given time.)
d. 指定一名詞組在一動作後果影響下的地點 (The V + ‘zai’ pattern specifies the location of a noun resulting from an action)
e. 表示一既定事實的前提 (The pattern ‘zai’… xia presents the circumstances, the pre-conditions of a given-fact)
我們參考上述資料,使用 Chinese Web corpus 2017 Traditional 這個包含 24 億個繁體中文詞彙的語料庫,從中隨機抽樣的小量語料(1000 句),並額外新增了成語以及問句共七類以涵蓋所有範例,確保模型能有效掌握不同句型所對應之語法功能,以利其進一步生成輔助學習的相關說明,之後將語料用Articut / LOKI 系統 [3] 以前面提到的功能詞為參照點,進行中文斷詞(Chinese Word Segment,CWS)、詞性標註處理(Part of Speech,POS)、命名實體辨識(Named Entity Recognition,NER),以語料庫中字數較少的句子「我在臺灣」為例,我們能從功能詞「在」開始,依據「在」有引介某人或某事的地點的功能這一事實,判斷其前後詞組的詞性,同時,我們也考量到現代漢語二字化的特性,進一步確認「臺灣」是一個合理的名詞組。
完成上述處理後,我們用正規表示式(Regular Expression, Regex)把具有代表性的詞組結構形式化和模型化。
首先,句子「我在臺灣」經過上一節的處理後,以下例中的字串呈現,此字串依序為「實詞_代名詞」標記的詞彙「我」,接著帶有「功能詞_內向功能詞」標記的詞彙「在」,最後接著帶有「地點」標記的詞彙「臺灣」組成的結構。「我在臺灣」的 Regex 如下:
<ENTITY_pronoun>我</ENTITY_pronoun>
<FUNC_inner>在</FUNC_inner>
<LOCATION>臺灣</LOCATION>完成後,系統會進一步將此句型形式化為以下 Regex。該 Regex 表示一段文本,其中包含零個或一個 (以 ? 表示) 帶有「實詞_代名詞」標記的任意「非標記字符」的字符串 (以 ^< 表示),接著零個或一個帶有「功能詞_內向或外向功能詞」標記的任意「非標記字符」,最後接著帶有「地點」標記的詞彙「臺灣」。

然而,此 Regex 僅能匹配包含「地點」為「臺灣」的句子,且字串中的三個詞組必須分別對應「實詞_代名詞」、「功能詞_內向或外向功能詞」及「地點」,才能被系統判定符合句型。為了合理擴大此句型所涵蓋的句子範圍,需對該 Regex 進一步調整。 本研究首先移除 Regex 中帶有「實詞_代名詞」標記的詞彙「我」,因為其存在與否並不影響此類句型中「在」引介某人或某事所在地點的功能。接著,將帶「地點」標記的詞彙「臺灣」更改為零個或多個 (*?) 任意帶「地點」標記的「非標記字符」。經過調整後的以下 Regex 即可匹配所有經斷詞後包含句型「在 + 地點」的字串。
<FUNC_inner>在</FUNC_inner>
<LOCATION>[^<]*?</LOCATION>而這種方法也不是僅見於 Loki 中。Apple 於 2024 年發表的研究論文 [4],也用了類似的方式將圖一左側的 "Sophie"、"nephew"、"31"、"8"... 等稍後要操作的元素,轉為右側的 {name}、{family}、{x}、{y}... 等標記。差別只在 Loki 使用 XML 搭配 Regex,而 Apple 的論文裡使用 Symbolic Template 來產生可操作的標記而已。

圖一:Apple 論文裡使用 Symbolic Template 來產生可操作的標記
再者,因應 Articut / Loki本身系統設計考量,並非所有書中歸類為地點的詞組都被視為帶有「地點」標記的詞組,比如字串「彰化縣員林鎮山腳路5段312巷160號」(取自語料庫),根據「…縣…市/鎮…」這樣的常見地址結構,即在命名實體辨識時被判斷為帶有「地址」標記的詞組,此時為維持系統中句型的易讀性,本研究另外建入新的句型以匹配含有「在 + 某地址」的句型。
另一例中,如同「90.6公里處」(取自語料庫)一類的地點表示方式亦常見於語料庫中,本研究則新增相應句型,匹配含有「功能詞_內向功能詞: 在」+ 任意量測詞組 + 「實詞_系統推測名詞: 處」的字串。PyLiteracy 即是依此方式觀察由語料庫中抽樣的句型後,將尚未建於模型中的文本經形式化處理後,調整以 Regex撰寫於模型中,如圖二所示。

圖二:模型建立及 Regex 編寫範例
模型建立完成後,Articut/Loki 將自動生成用於串接模型進行應用的 python 程式碼,程式碼中含有針對「在」的不同語法功能之下各句型的匹配判斷程式碼,設計者可於各句型底下的程式碼區塊撰寫程式碼,以在匹配到該句型之後進行進一步篩選、抽取指定詞彙或撰寫匹配完成後的處理機制。
設計應用時,可於「在」引介地點的語法功能的類別下,針對不同句型,抽取表達「地點」的詞組並加以撰寫相關說明,針對使用者輸入的文本詳述相關語法。如下圖所示,「馬來西亞」、「新竹市東區大學路1001號」、「64.8公里」及「處」等詞彙,可以被獨立抽取並用於解說回覆中,系統可依據使用者給予的文本,標示出表示地點的詞組,進一步解釋現代繁體中文中表達地點的方式以及「在」引介地點的語法功能。

圖三:針對不同句型抽取指定詞彙及撰寫相關說明

圖四:依照抽取之詞彙生成相應說明
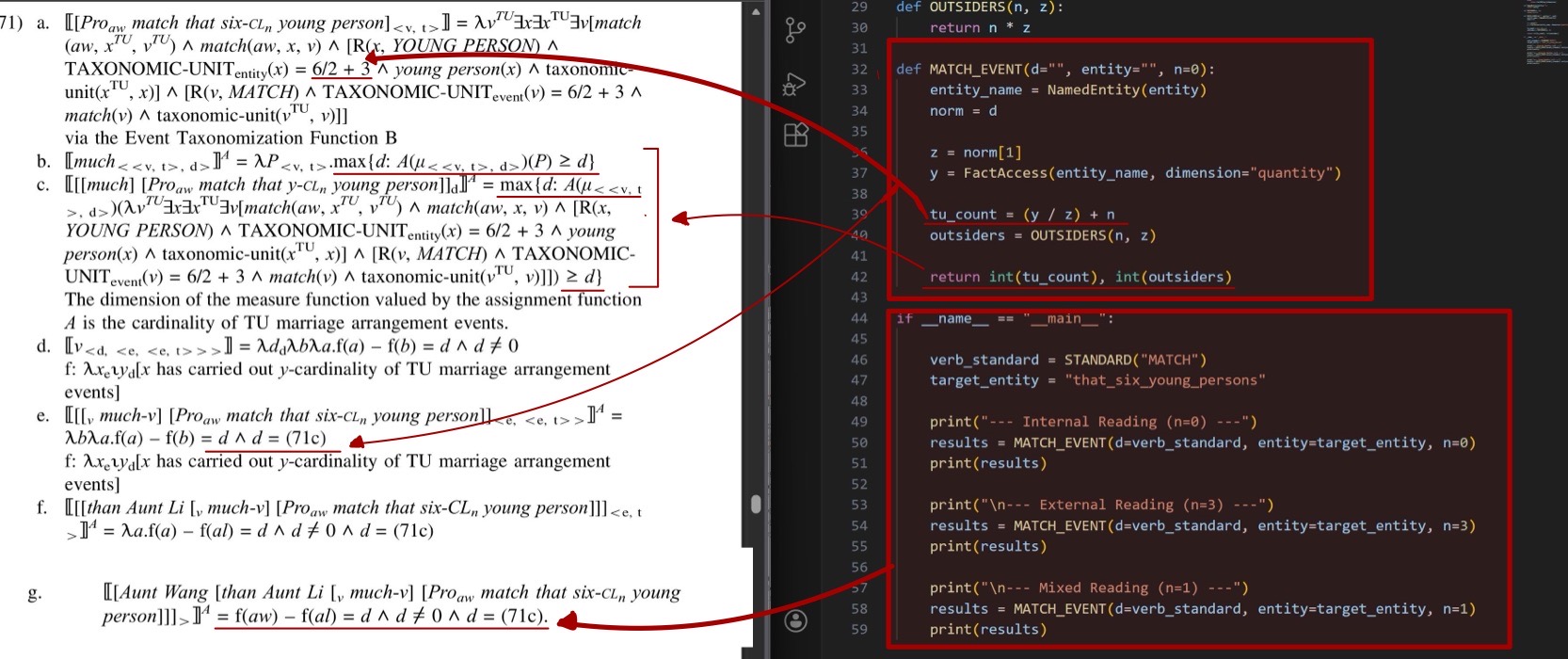
最後,我們設計簡單的介面(interface)串接 pyLiteracy 與使用者互動,獲取輸入文本進行比對及分析處理,我們圖五演示的邏輯設計文法檢查的系統流程。

圖五:串接語法檢查模型之設計邏輯
在獲取使用者輸入之文本後,系統會先將文本分句處理,此步驟目的主要為減少單次運算所需時間以及避免未正確分句的文本造成判斷錯誤,分句之後,系統將逐句將文本以 Articut 進行進行斷詞、詞性標註及命名實體辨識處理,並將帶有詞性標記的字串與模型中的正確句型進行匹配,若字串帶有「實詞_功能詞:在」,但該字串句型不存在於模型中,則模型會判斷此句中「在」使用錯誤,並根據輸入之文本及相應語法功能產生說明文字做出回應。
我們針對語料庫中其他包含「在」和「再」的語句,以上述方式建立之模型進行測試。其中,針對含有「在」,包含七種語法功能分類、158 種句型的模型在 10000 句含有「在」的語料中,正確辨識了 9126 句的使用情形(正確、錯誤及語法功能類別),正確率約 91%;而針對「再」,包含 35 種句型的模型正確辨識了 8859 句測試句中的 8468 句(正確及錯誤),正確率約 95.6%。其中,模型檢查含有「再」的句型結果,與語料庫內分類結果不一的 391 句中,約有 40% 為過於口語、不完整或存在歧義的句子,比如「再。」或「再…再…再」等;除此之外,其餘未判斷正確的句子均屬尚未被建入模型中之句型,可預期模型中的句型在經過小幅擴增後,能在語法檢查任務上達到更高的涵蓋律及準確率。
相對的,我們也對 LLM 做了一些測試,考量到Chinese Web corpus 2017 Traditional包含 24 億個繁體中文詞彙的大型語料庫,LLM 的部分訓練資料很可能源於此,我們搜尋語料庫中含有「再」的語句進行觀察,僅以人工隨機查閱的方式即可在有限的觀察範圍內,發現如下例中將「在」誤用為「再」的例子。
將「在」誤用為「再」(取自Chinese Web corpus 2017 Traditional):
再妝感的部份強調眼粧和肌膚的清透
族人已不再此生活
本金再第4個月一定全額付清希望有人能幫助我貸款留言
小弟再此3Q得Orz
沒有的話看要不要考慮買再北市或遷戶口把
再木柵窄小昂貴的別墅
我們以 ChatGPT (GPT-4o) 為測試對照,以提示詞:「grammar check: 」進行測試,結果顯示 ChatGPT 忽略了上述語料庫中的錯別字。此測試即說明大型語言模型可能因訓練資料中存在錯別字,而忽略文句中的錯別字。

圖六:ChatGPT (GPT-4o) 忽略錯誤訓練文本中的錯別字
我們進行這個實驗並不是想表達 LLM 不好,而是想實際應用簡單的語言學知識,驗證這些形式化的分析是否真的能實現「在接受這麼少的前提的情況下,知道這麽多」的效果。我們的實驗成果顯示 pyLiteracy 在文法檢查這類小型 NLP 任務中的表現十分出色。最重要的是,仰賴更貼近人類對語言的理解方式,它能用相比於 LLM 而言,非常非常少的資源就完成任務,在這個專案中,我們用非常非常少的語言學知識就省下了非常多的資源。
現代語言學從 1957 年發展至今 [5],已經針對人類語言提出許多通盤原則性分析 (generalization),而在 1993 年 Noam Chomsky 提出「極簡方案(Minimalist Program)」後 [6],語言學家致力從運算效率(computational efficiency)的角度將分析最簡化 [7],如果你對「語言」有興趣,別錯過這些!它或許能成為資訊系統掌握人類語言的一個突破點呢!
註解
生成語言學 (generative linguistics) 的名稱有兩點常見誤解值得澄清。第一,generative linguistics 在臺灣常被翻譯為「形式語言學」(formal linguistics),這個翻譯讓一些學者產生不必要的誤解,認為「形式語言學僅關注形式表象」,這不是正確的理解。形式語言學之所以被稱為「形式」,是因為它運用數學和邏輯形式符號化 (formal symbol) 的系統和方法,應用於描述與分析語言現象,目標是構建明確的理論模型,捕捉自然語言的結構和規則,以便進行嚴格的測試和分析。第二,人工智能領域也使用 ”generative” 一詞,如「生成式人工智能」 (generative AI) 以及 ChatGPT 之中的 G 就是 “generative” 的縮寫。然而,目前以深度學習為主流的人工智能領域對於這個詞的定義與生成語言學的定義是完全不同的。前者的 ”generative” 是指基於海量數據檢索並結合加速計算的詞元 (token) 預測生成技術;後者的定義是運用有限且明確的語法規則,生成符合語法的句子。
Yang, Charles. 2013. Who’s afraid of George Kingsley Zipf? Or: Do children and chimps have language? Significance 10(6): 29–34.
Wang, Wen-jet, Chen, Chia-jung, Lee, Chia-ming, Lai, Chien-yu, Lin, Hsin-hung. 2019. Articut: Chinese Word Segmentation and POS Tagging System [Computer program]. Version v.258, https://api.droidtown.co.
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, Mehrdad Farajtabar. 2024. GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. arXiv:2410.05229 [cs.LG]
Chomsky, N. 1957. Syntactic Structures. The Hague: Mouton.
Chomsky, Noam. 1993. A minimalist program for linguistic theory. In Hale, Kenneth L. and S. Jay Keyser (eds.). The View from Building 20: Essays in Linguistics in Honor of Sylvain Bromberger, 1–52. Cambridge, Massachusetts: MIT Press.
Stabler, Edward P. 2012. Computational Perspectives on Minimalism. In Cedric Boeckx (ed.), The Oxford Handbook of Linguistic Minimalism.
其他參考文獻
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
文章分類
標籤
作者介紹

陽明交通大學外國語文系
國立陽明交通大學向以理工、醫學及管理見長,有鑒於科技的發展宜導以人文的關懷、博雅的精神,而資訊的流通則取決於語文的運用,因此於民國八十三年八月成立外國語文學系。
本系發展著重人文與科技之深層多元整合,以本系文學、語言學之厚實知識素養為底,再廣納本校資訊理工、管理、醫學以及其他人社領域等豐厚資源,創造多元與融合的學術環境,開拓具前瞻性及整合性之研究與學習,以培養兼具系統性思考及人本軟實力的學生,使其成為兼具在地及國際性多層次觀點與分析批判能力的未來領導者。
在研究所的規劃上,語言學方面主要是結合理論與實踐,特別重視學生在基本語言分析及獨立思考能力上的訓練。除語言各層面的結構研究外,本系也尋求在跨領域如計算機與語言的結合及語言介面上之研究 (如句法語意介面研究)能有所突破,並以台灣的語言出發,呈現出台灣語言(台灣閩南語、台灣華語、南島語)多樣性,融入社會觀察,如自閉語者聲學、聽障相關研究、社會語音學研究以及台灣語言的音變等。
相關文章
當形式語意遇上程式碼:我在《語言科技與複雜系統》課程中的思維轉變
在修習《語言科技與複雜系統》這門課之前,對於語言與科技的關係我抱持著一種二元分立的觀點。我之前以為語言學僅能提供靜態的規則參考,而 AI 則是負責暴力運算的工具,兩者僅止於表層的應用結合。然而這學期的理論探討與程式實作,改變了我對這兩個領域互動關係的認知。

原來簡短回答不是懶惰?——專訪句法學家劉啟明
為什麼中文可以理直氣壯地省略主語、賓語(受詞),只丟出核心詞彙就能精準傳達語意,而英文卻必須補上那些看似多餘的 "I", "it" 或 "the” 呢?這種「形式與語意不對等」(form–meaning mismatch)的現象,正是句法學家劉啟明老師,在語言學界長年耕耘的核心議題。